Reflection Journal
📝Week 2
During this week's website creation and hosting workshop, I deeply engaged in the entire process from building a personal webpage to uploading it to the server. Though basic, this experience gave me an intuitive understanding of the digital media development environment. By creating and uploading HTML files myself, I realized that practical application of technical knowledge is more challenging than theoretical learning. I made several mistakes due to unfamiliarity with HTML tags, which reminded me that mastering technology requires continuous practice and debugging. I also reflected on the deeper significance behind web design. A webpage is not just a platform for information display but a reflection of personal or organizational digital identity. While designing structure and content, I became aware of how layout, color, and other elements convey specific information and values. Uploading the webpage to the server and making it publicly accessible made me consider the balance between openness and privacy. The internet offers a broad platform for personal work display, but protecting personal data and privacy in open space remains a critical issue to explore.
📔Week 3
In this week's learning about web crawlers, I was amazed by their powerful data retrieval capabilities. Using tools like OutWit Hub, I could easily extract required information from webpages, showcasing the efficiency of web crawlers. However, this also raised ethical considerations. The use of web crawlers involves data ownership and privacy issues. Extracting data may infringe on rights if permission is not obtained. Moreover, crawlers can burden servers, affecting regular user experience. From a research perspective, crawlers provide abundant data, but the accuracy and reliability of this information can be uncertain, impacting research results. Therefore, rigorous validation and screening of data are necessary. Additionally, with evolving technology, anti-crawling mechanisms are improving, requiring us to explore data acquisition methods within legal and ethical boundaries.
📓Week 4
This week's data collection workshop helped me understand the nature and value of data more deeply. Designing a survey on students' use of generative AI made me realize that data collection is not a simple listing but a subjective, goal-oriented process. The setup of each question can influence data direction and interpretation. Ethical issues run through the process; obtaining consent is not just procedural but a matter of respecting participants' rights. I reflected on power dynamics in data collection, as data collectors can define questions, select variables, and interpret data, which may lead to biased interpretations. Maintaining humility and openness is essential to avoid misuse of power.
📒Week 5
This week's data visualization workshop helped me realize that data visualization is not just turning data into charts but a powerful storytelling tool. Using Excel and Tableau Public, I attempted to convert data into visual charts, realizing that each choice affects communication and audience understanding. Selecting chart types like bar, line, or pie emphasizes different data aspects, influencing audience conclusions. This highlights the responsibility of visualization designers. Audience considerations, data accuracy, and aesthetics must be balanced to ensure effective communication without misleading interpretation.
🗒️Week 6
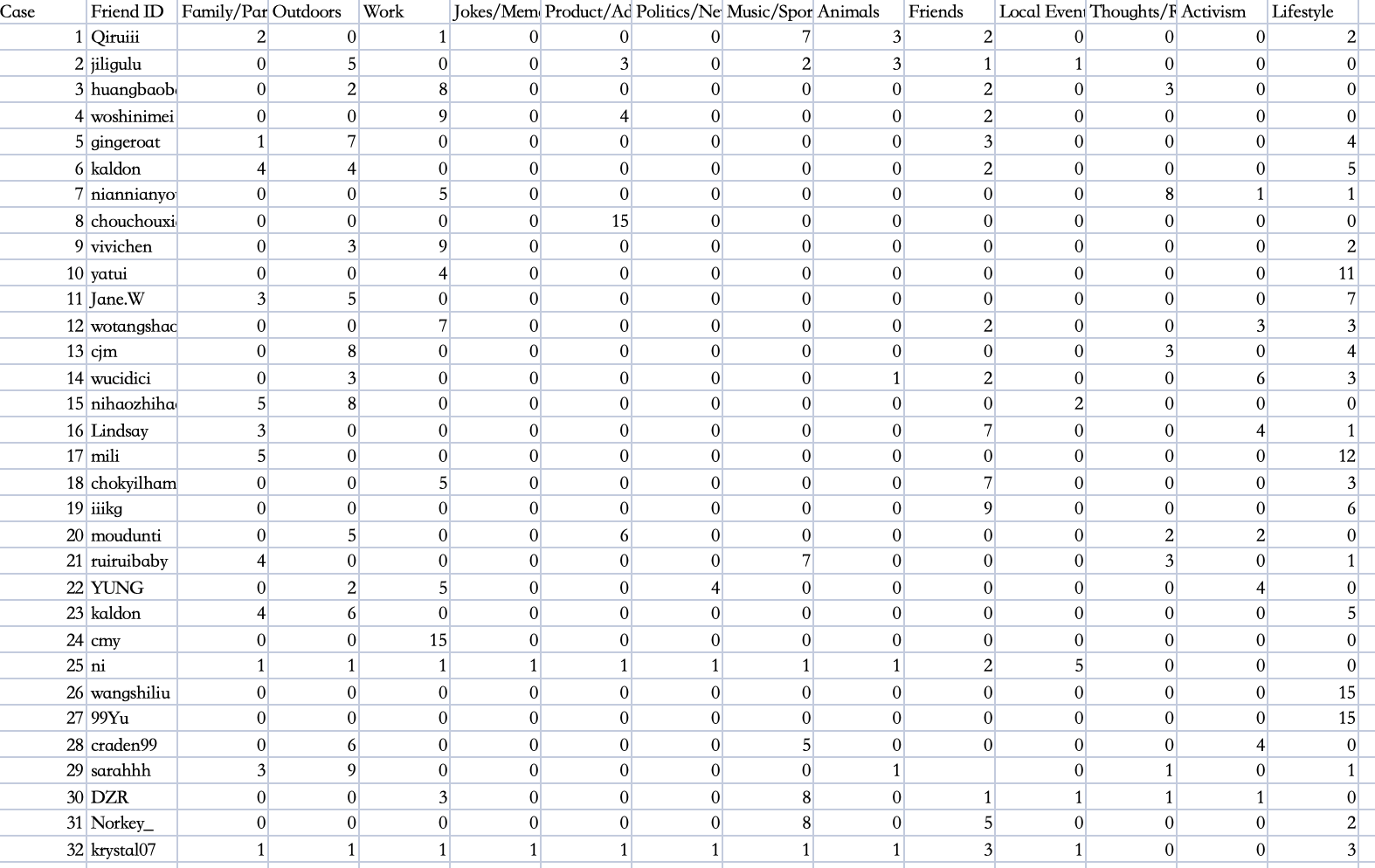
During this week's workshop, I selected 32 accounts from my Weibo list, mainly including real-life friends. I recorded their latest 15 original Weibo posts (excluding pure retweets), took screenshots of the content, and numbered and organized them into a portfolio. Next, based on Sumpter (2018)'s 13 categories, I encoded the content. In the Weibo environment, I needed to constantly perform situational translation, for example, many Weibo posts mixed daily jokes and emoticons. I had to make a choice between "jokes/memes" and "thoughts/reflections". According to the task requirements, each Weibo post could only be classified into one category. In Excel, I used 32 users as rows and 13 categories as columns, counting the frequency of posts in each category for each user, forming a 32 by 13 matrix. Subsequently, I drew several two-dimensional scatter plots based on teaching suggestions, such as "work vs family/partner", "politics/news vs lifestyle", "jokes/memes vs thoughts/reflections", attempting to observe if there were any obvious clustering or correlations. I reflected on to what extent our control over identity is controlled by algorithms. Shared content, search history, and browsing habits are interpreted to predict interests and preferences, but are these predictions accurate? Examining the output results of advertising profiles reveals biases in algorithmic classification, which can affect user experience. The construction of algorithmic identity is dynamic, but is constrained by platform design and data collection. Manually classifying posts by friends highlights the complexity and subjectivity of data classification.
📝Week 7
During this week's workshop on AI and identity, interacting with ChatGPT led me to new reflections on the relationship between identity, algorithms, and generative AI. While completing the “negative prompt” task, I realized that AI storytelling is not fully controllable; outputs are shaped by patterns and biases within training data. This raised important questions about whether AI reinforces existing stereotypes or opens new perspectives. I also considered the concept of “computational experience”—our relationship with computational tools is not simply user versus object but a co-created experience that shapes cognition and behavior. Engaging with AI may shift how we understand our own identities and how we interpret the world. Furthermore, discussions of “predictive and probabilistic tendencies” and “heterogeneity” highlighted the complexity of generative AI. Its outputs are never fixed but probabilistic, creating both creative possibilities and unpredictable outcomes. This made me reflect on how diverse data and models could be leveraged to support innovation while acknowledging their limitations.
📔Week 8
In this week's digital ecology practice workshop, I explored the human–food ecology of Kirkgate Market through the combination of sensory and digital methods. Using my phone to take photos, record audio, and write notes helped me capture different aspects of the market experience, but I also became aware of the limitations of digital tools. Cameras cannot record smell or taste, and these missing sensory dimensions made me question how technology mediates our understanding of food. I also reflected on how digital technology contributes to transparency in food systems, giving consumers access to information about origin, production, and nutrition. However, this transparency can create new challenges, such as information overload or potential misinformation. This led me to rethink digital technology’s role: Should it help us better understand and protect food ecologies, or can it unintentionally create new complexities?


📓Week 9
In this week's creative hacking and Arduino workshop, I experienced the hands-on process of building a simple digital system to measure human temperature. This practice deepened my understanding of the relationship between digital media, data, the body, and perception. I realized that creative hacking is not just technological innovation but also a rethinking of existing systems. Combining components to create new functions revealed both the challenges and rewarding aspects of building interactive systems. Troubleshooting errors—such as coding bugs or hardware faults—highlighted the iterative nature of creative experimentation. Although Arduino provides an accessible platform for beginners, its limitations in processing power and storage prompted me to think about maximizing creativity within constraints. I also reflected on the broader significance of creative hacking: it challenges technological norms, opens new possibilities, and enables alternative ways of engaging with digital media.
🗒️Week 10
This week's workshop on digital storytelling gave me new insights into the diversity and complexity of narrative forms in the digital age. Comparing linear and non-linear narratives made me realize how non-linearity expands storytelling possibilities, enabling shifts across time and perspective and increasing interactivity. However, this complexity may also confuse audiences, demanding greater cognitive effort. Our discussion of interactive narratives further emphasized the role of the audience as co-creators—capable of influencing story direction and outcomes. This interactivity enriches engagement but requires careful design to account for multiple pathways and responses. I also reflected on digital storytelling’s cultural and social significance: it is not only entertainment but a medium for expressing ideas, exploring issues, and provoking reflection. Digital storytelling can support social change and cultural development, inspiring me to explore more possibilities in future creative practice.